この記事は、YOLOの論文を紹介したいと思います。
※説明の都合上、図表など省略しています。適宜、元論文も参照してみてください。
"You Only Look Once: Unified, Real-Time Object Detection"
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
1. どんなもの?
YOLO(You Only Look Once)は、リアルタイムの物体検出のための統合されたニューラルネットワークモデルです。このモデルは、物体の検出を単一の回帰問題として扱い、画像全体を通して複数のバウンディングボックスとそのクラスの確率を同時に予測します。全ての処理が一つのネットワーク内で完結するため、高速に動作することが可能で、基本モデルは秒間45フレーム、Fast YOLOと呼ばれる小さなネットワークバージョンでは、秒間155フレームの処理速度を実現しています。
YOLOの利点は次のようなものがあげられます。
速度
YOLOはリアルタイム処理に非常に適しており、秒間45フレーム以上の処理速度を達成しています。これは、オブジェクト検出のために複雑なパイプラインを必要とせず、単一のネットワーク評価で検出を完了することができるためです。
画像全体を考慮
YOLOはトレーニングとテスト時に画像全体を考慮します。これにより、画像内のオブジェクト間の関係や文脈情報を捉えることができ、より正確な検出が可能になります。これは、部分的な情報に基づく従来の方法とは対照的です。
一般化能力
YOLOは一般化されたオブジェクトの表現を学習します。自然画像から芸術作品まで、異なるドメインへの一般化能力が高いです。これは、画像全体から直接学習する能力と、高度な文脈情報を利用することにより実現されています。

2. 先行研究と比べてどこがすごい?
YOLOは単一の畳み込みニューラルネットワークを使用して、バウンディングボックスの位置とクラス確率を直接予測します。これに対して、以前の物体検出モデル(例えばR-CNN)は、領域提案を行い、それぞれの提案に対して個別に分類器を適用する複数ステップのプロセスを必要としていました。YOLOのアプローチは、これらすべてのステップを一つのネットワークに統合することで、処理の複雑さを大幅に減少させ、リアルタイムのパフォーマンスを実現しています。
3. 技術や手法のキモはどこ?
3.1. 単一のネットワーク
YOLOは画像全体を一度に処理し、複数のバウンディングボックスとクラス確率を直接予測します。これにより、画像から特徴を抽出し、それを用いてオブジェクトの位置とクラスを同時に予測する一連のプロセスを単一のネットワークで完結させています。

YOLOのネットワーク構造は、画像認識における効果的なアーキテクチャの一つであるGoogLeNetから着想を得ています。具体的には、GoogLeNetが導入したインセプションモジュールと同様のアイデアを取り入れつつも、YOLOでは異なるアプローチを採用しています。
入力される画像のサイズは3×448×448となっており、これにより高解像度の画像からも細かい特徴を捉えることが可能です。ネットワークは合計24個の畳み込み層から構成されており、その後に2つの全結合層が続きます。GoogLeNetで重要な役割を果たしているインセプションモジュールの代わりに、1×1の縮小層の後に3×3の畳み込み層を単純に使用しています。
3.2. グリッドシステム
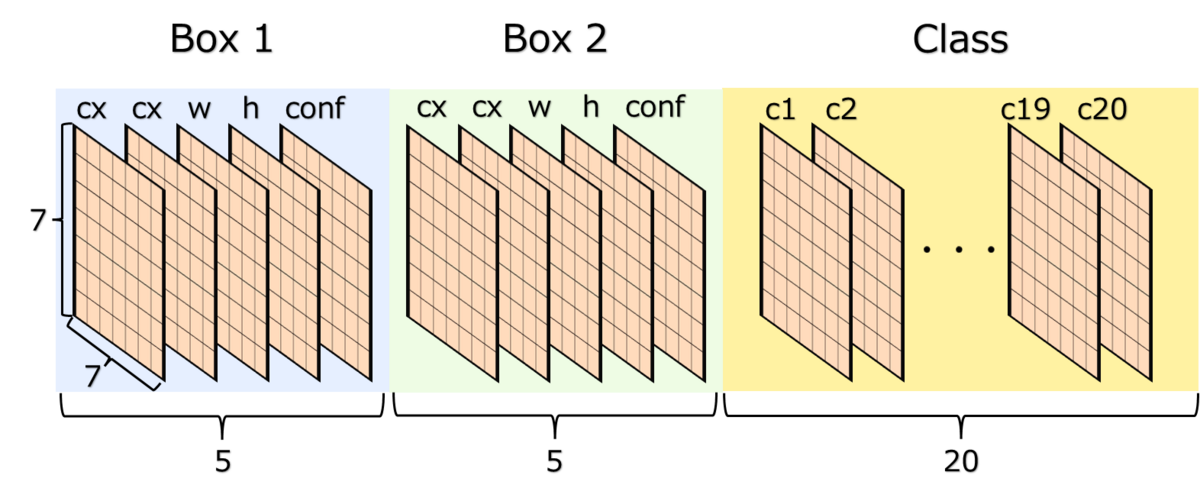
YOLOは画像をのグリッドに分割します。YOLOは各グリッドに対して予測を行いバウンディングボックスとクラス確率を出力します。しかし、すべてのグリッドの予測結果を使用するわけではありません。

学習時の損失計算で使用するものは、物体の中心座標が存在するグリッドのみになります。具体例で示すと画像中には「犬」「自転車」「車」の3つの物体が存在します。それぞれの物体中心は画像中に記載しました。物体の中心座標が存在するグリッド①, ②, ③の予測結果と正解データを使用して損失を計算します。

バウンディングボックスの予測では、各グリッドごとにB個のバウンディングボックスと、そのを出力します。バウンディングボックスは、
から構成されます。
は物体の中心座標で、
は物体の幅と高さになります。
はモデルがそのバウンディングボックス内に、物体を含んでいるとどれだけ自信があるか、予測されたボックスがどれだけ正確かを表します。
は次の式で表されます。
ここで、は物体の中心座標の存在有無を表し、中心座標が存在していれば
と、存在してないければ
を表します。
は、予測されたバウンディングボックスと正解データのバウンディングボックスの
となります。
クラス数をとしたとき、クラス分類の予測では各グリッドごとにオブジェクトが含まている場合の条件付き確率
を予測します。
個のボックスごとではなく、グリッドごとに1つのクラス確率を予測します。
以上をまとめると、YOLOモデルから出力されるデータは、の形となります。
※図中ではとして記載しています。
3.3. 損失関数の設計
最初の20の畳み込み層に対して、ImageNetを使用して事前トレーニングを実施しています。その後にプーリング層と全結合層を配置しています。ネットワークへの画像の入力サイズをから
に増やしています。
最終層はクラス確率とバウンディングボックスの座標の両方を予測します。バウンディングボックスの幅と高さを画像の幅と高さによって正規化し、0と1の間に収まるようにします。バウンディングボックスのxとy座標は特定のグリッドセルの位置からのオフセットとしてパラメータ化され、これもまた0と1の間に収まります。
損失関数は次のように定義されます。
損失計算時の注意点を説明します。YOLOモデルは個のバウンディングボックスを出力しますが、損失計算時に
個のバウンディングボックスをすべて計算に使用するわけではありません。
個のバウンディングボックスのうちで正解データとの
が高い方のバウンディングボックスのみを計算に使用します。
これを踏まえて、損失関数の各項について解説します。
第一項目はバウンディングボックスの中心座標の損失を計算します。
はグリッド
に物体の中心座標があり、
個のバウンディングボックスのうち
が一番高い
番目のバウンディングボックスであれば
となり、そうでなければ
となります。損失としては二乗和を計算しています。
を掛けるのはバウンディングボックスに関する損失を大きく評価し、バウンディングボックスの損失をより重要視するためです。
第二項はバウンディングボックスの幅と高さの損失を計算します。
計算内容としては基本的には中心座標の損失計算と同様のものとなります。ただし、幅と高さの平方根を取ることに注意が必要です。これは大きなバウンディングボックスの小さい損失と小さなバウンディングボックスの損失を考えたときに、大きなバウンディングボックスの小さい損失はあまり重要視しないということを意味しています。
第三項目はの損失を計算します。
は中心座標や幅と高さのと同様です。
はYOLOモデルから予測された
となり、
はYOLOモデルから予測されたバウンディングボックスとラベルデータの
となります。
第四項目は物体が存在しないグリッドのの損失を計算します。
は、対象のグリッド内に物体が存在しない場合は
となり、物体が存在する場合は
となります。物体が存在しないので
となります。物体が存在しないグリッドの
を
に最適化することで、モデルが不必要なエリアに高い
を割り当てることを防ぎ、全体としての検出精度を向上させる効果があります。
を掛けるのは、ほとんどが物体が存在しないグリッドであり、物体が存在するグリッドとのバランスをとるため、損失の影響を少なくするためです。
第五項目はクラス分類の損失となります。
は中心座標や幅と高さのと同様です。クラス分類の損失関数としてクロスエントロピーではなく二乗和として定義されています。クラスに関する出力は各グリッドに一つしかないため、単純に正解データとの二乗和を計算します。
3.4. 推論
YOLOモデルはの各グリッドについて推論結果が出力されます。この中のほとんどが物体の存在しないバウンディングボックスとなっており、推論時に不要なバウンディングボックスが含まてしまいます。
そのため推論時には、不要なバウンディングボックスを取り除き、物体の存在するバウンディングボックスだけに絞る処理を行います。YOLOモデルから出力された各グリッドのと条件付きクラス確率を掛けたものを使用して、一定の閾値以上のものだけを採用します。
これにより、そのクラスがバウンディングボックス内に出現する確率と、予測されたバウンディングボックスがオブジェクトにどれだけ適合しているかの二つの情報を表現します。
上記の処理で不要なバウンディングボックスを削除しても、同じ物体に対して複数の重複するバウンディングボックスが出力されることがあります。重複するバウンディングボックスを削除するためにNMS(Non-Maximum Suppression)を実施します。
4. どうやって有効だと検証した?
Fast YOLOはPASCAL VOC 2007で最も高速な物体検出方法であり、当時、最も高速な物体検出器です。52.7%のmAPで、他のリアルタイム検出器の2倍以上の精度を達成しています。YOLOは63.4%のmAPを達成し、リアルタイム性能を維持しながらも、さらに性能も向上しています。

YOLOはVOC2012のテストセットに対して57.9%のmAPを記録し、当時のSOTAより低い結果ですが、R-CNN using VGG-16 (59.2%)に近い結果となっています。

5. 議論はある?
YOLOはリアルタイムの物体検出を可能にしますが、次のように制約が存在します。
近接オブジェクトの検出
YOLOは各グリッドセルが最大で2つのオブジェクトのみを検出できるため、密集したオブジェクトの群れ(例えば鳥の群れなど)を検出する際に性能が低下します。
-
新しいまたは珍しいアスペクト比や物体に対する一般化が難しいことがあります。YOLOのアーキテクチャはダウンサンプリングを多用しており、細かい視覚情報が失われるため、特定の形状やサイズのオブジェクトに対する予測が不正確になることがあります。
小さいオブジェクトの検出
YOLOは全体的な画像コンテキストを利用するため、小さなオブジェクトが複数存在する場合にそれらを見逃すことがあります。これはネットワークが大きな特徴を重視するため、小さな特徴が見過ごされがちになるからです。
局所化
小さなバウンディングボックスのエラーと大きなバウンディングボックスのエラーを同等に扱います。大きなボックスの小さな誤差は一般に無害ですが、小さなボックスでの小さな誤差はIOUにおいてはるかに大きな影響を与えます。